


Einleitung
Vor einiger Zeit fragten mich meine Arbeitskollegen, ob ich ihnen die Grundlagen von A.I. (Artificial Intelligence) auf einfache(!) Weise erklären könnte. Da viele von ihnen nicht so tief in IT und Mathematik bewandert, überlegte ich wie man das grundlegende Prinzip stark vereinfacht verständlich aufzubereiten könnte.
Nach einiger Überlegung hatte ich die Idee, ein sehr stark vereinfachts Beispiel eines Chatbot basierend auf den Grundprinzips eines Large Language Models (LLM) zunehmen.
Beim erstellen der Präsentation für meine Kollegen kam mir die Idee diesen Vortrag auch hier in meinem Blog für die Allgemeinheit zu veröffentlichen.
Grundlagen
Was heute als A.I. (Artificial Intelligence) bezeichnet wird, basiert im auf Methoden des Machine Learnings (ML). Die theoretischen Prinzipien dahinter wurden bereits in den 1960er Jahren entwickelt. Im Wesentlichen handelt es sich um fortgeschrittene Statistik und Wahrscheinlichkeitsberechnungen. Damit diese Methoden jedoch sinnvolle und nützliche Ergebnisse liefern können, ist die Analyse großer(!) Datenmengen erforderlich.
Erst durch die rasanten Fortschritte in der Rechen- und Speicherleistung in den letzten Jahren wurde es möglich, Machine Learning auf einem akzeptablen Niveau in der Praxis umzusetzen. Insbesondere die Entwicklung spezieller Hardware, wie Parallel-Vektor-Prozessoren, ursprünglich für Grafikkarten und Krypto-Berechnungen gedacht, haben das Machine Learning entscheidend vorangebracht.
Phasen
Der Prozess zur Erstellung eines A.I.-Modells gliedert sich in drei grundlegende Phasen:
- 1. Programmierung des Basis-Modells:
Das Grundmodell wird manuell programmiert und legt den Regeln fest, innerhalb dessen das eigendlich Machine Learning stattfindet. - 2. Anlernen des Modells:
Hier findet der eigentliche Machine-Learning-Prozess statt. Dieser Schritt ist extrem rechenintensiv, da hier automatisiert sehr große Datenmengen analysiert werden. Auf Basis dieser Analysen wird das Modell verfeinert. - 3. Nutzung des fertigen Modells:
Das fertig trainierte Modell kann nun verwendet werden. Während es immer noch mehr Rechenressourcen benötigt als für normale Programme, ist der Anforderungen sind nicht mehr so hoch wie beim Anlernen.
Je nach Anforderung kann es mehrere aufeinander aufbauende Programmier- und Anlernphasen geben.
Vorab-Informationen
Noch mal der Hinweis, dass dieses Beispiel sehr stark vereinfacht ist. Es zeigt eine Variante an wie man ein LLM aufbauen kann. Alle wichtigen Steps sind zwar vorhanden, aber gerade bei den Feinheiten (Tiefe) der Steps bleibe ich bewusst an der Oberfläche.
Für eine grundlegende Einführung, die auch für IT-Laien verständlich sein soll, sollte dies ausreichend sein.
Es folgen einige Erläuterungen zu Begriffen und Konzepten:
- Worte bezieht sich auf alle linguistischen Bausteine eines Textes, inklusive Satzzeichen, Zeitformen wie „-ed“ (bei englischen Verben), Plural-Suffixen, Possessiv-’s, etc.
Aber auch bewusste Zeilenumbrüche, Neuer Absatz, Neues Kapitel, EndOfText, etc. - Text steht für jegliche Art von Textdokumenten, seien es Bücher, Artikel, Nachrichten, Social Media oder andere Inhalte.
- -wert und -faktor stehen für 64-Bit-Faktoren. Im Prinzip das gleiche wie Prozentwerte, nur zwischen 0 und 1.
- Modell ist ein Schema nach dem Eingaben verarbeite werden.
Hier beginnt die erste Programmiere- und Anlern-Phase.
1. Programmierung – Teil I
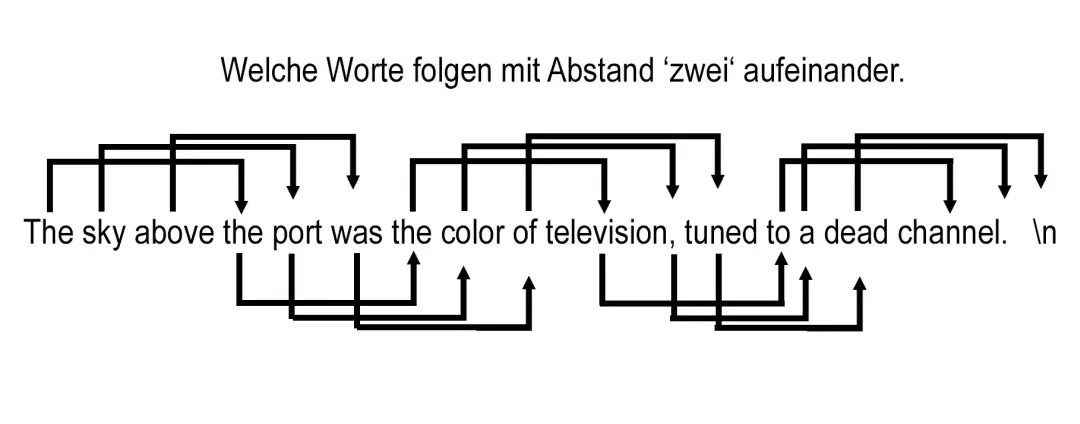
Im ersten Schritt wird ein Programm entwickelt, dass die Wahrscheinlichkeit von bestimmten Wort Abfolgen in einem Text analysiert.
- Ermittlung der Unique Worte
Alle im Text vorkommenden einzigartigen Worte werden identifiziert.
Diese werden in eine Tabelle erfasst und zwar sowohl als als Zeilen und als Spalten.
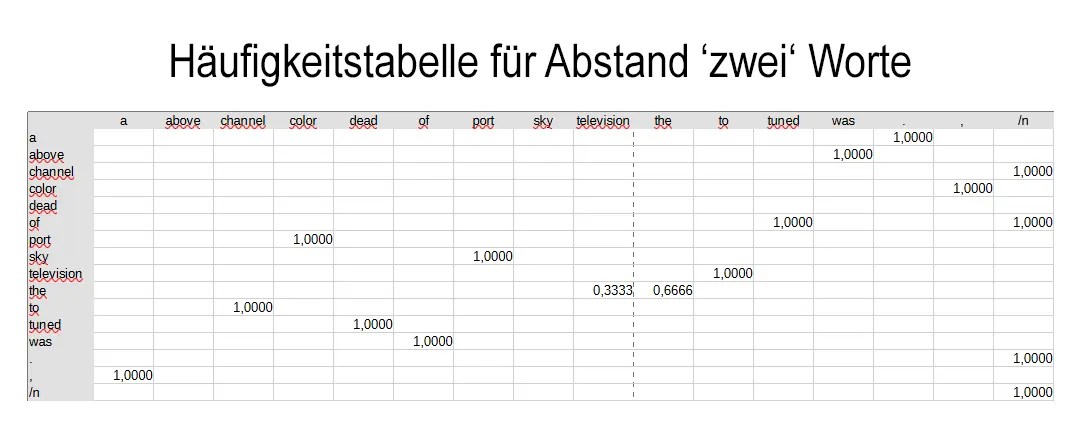
So das ein Raster der Unique Worte entsteht. - Füllen der Häufigkeitstabelle für direkt aufeinanderfolgende Worte
Die Zeilen repräsentieren Worte und die Spalten welche Worte direkt auf dieses Wort folgenden.
In den Tabellenfeldern wird der Wert der relative Häufigkeit mit der diese Worte aufeinander folgen eingetragen.


- Erstellung weiterer Tabellen für Worte mit n-Wort-Abstand
Nach diesem Prinzip werden weitere Tabellen erstellt, welche dies für verschiedene Wortabstände wiederholt, beginnend mit einem Wort Abstand bis zu einem vordefinierten maximalen Wortabstand.
Die Größe des maximalen Abstands hängt von der gewünschten Genauigkeit und den verfügbaren Ressourcen ab. Ab einem gewissen Punkt übersteigt aber der Aufwand die zusätzliche gewonnen Genauigkeit.
Zusammengefasst:
Das Programm analysiert einen Text und wandelt ihn in mehrere Tabellen um. Diese halten für jedes Wort fest, welche Wörter wie häufig (relativ) darauf folgen und dies für verscheiden Wortabstände
Für die weitere Verarbeitung können noch zusätzlich Informationen über die entsprechenden Worte gesammelt werden, z.B. die relative Häufigkeit. Außerdem können noch weitere Infos über die Häufigkeit in Zusammenhang mit den entsprechen Quellen erfasst werden. Wie eine Klassifizierungen der Quellen nach z.B.: Text-Arten (Fachbuch, News, Social-Media, …), Alter/Jahrgang der Quellen, Einstufung der „Qualität“ der Quelle (Bild, TAZ, FAZ, …). Welche Daten hier noch sinnvoll sind ergibt sich aus den Anforderungen für die späteren Gewichtungsregeln.
2. Anlernen des Modells – Teil I
Dies Programm wird nun mit einer großen Anzahl von Texten gefüttert (VIELE !!). Diese Texte sollten ein sehr breites Spektrum abdecken – von Wikipedia-Artikeln über Fachbücher bis hin zu Nachrichten und Social-Media-Beiträgen. Je vielfältiger und umfangreicher das Textmaterial ist, desto besser wird das spätere Modell. Alle Analysen werden in gemeinsamen Tabellen für jeden Wortabstand zusammengeführt, wobei sich die relativen Häufigkeiten immer auf die gesamt Menge der Texte bezieht.
So entsteh eine sehr umfangreiche Übersicht welche Worte mit welchem Abstand und welcher Wahrscheinlichkeit aufeinander folgen.
im Zusammenhang mit ChatGPT meine ich mal eine Zahl vom 10.000.000 Worten (in verschieden Sprachen) gehört zuhaben.
Damit ist die erste Programmiere- und Anlern-Phase abgeschlossen.
Hier beginnt die zweite Programmiere- und Anlern-Phase.
3. Programmierung – Teil II
Im nächsten Schritt wird ein Programm entwickelt, dass auf Basis der vorher gesammelten Daten ermittelt, welches Wort mit der höchster Wahrscheinlichkeit auf einem definierten Textauszug folgen könnte.
- Erstellung eines Textauszugs
Per Zufall wird ein Auszug aus einem Text erstellt, der die Länge des maximalen Wort Abstands hat, der in Teil 1. festgelegt wurde. - Aufbau einer Analyse-Tabelle
Die Worte des Auszugs bilden die Spalten einer Analyse-Tabelle. - Ermittlung des nächsten Wortes
Für das letzte Wort des Textauszugs wird in der Häufigkeitstabelle für direkt aufeinander folgende Wörter (siehe 1.B.) geprüft, welches Wort den höchsten Wahrscheinlichkeitswert hat auf das Wort des Auszuges zu folgen.
Dieses Wort ist ein möglicher Kandidat als nächstes Wort auf den Textauszuges zu folgen. Für dieses wird in der Analyse-Tabelle eine Zeile angelegt und sein Wahrscheinlichkeitswert wird in das entsprechende Feld geschrieben


- Erweitern der Analyse-Tabelle
Dieser Prozess wird für jedes Wort des Textauszugs wiederholt, wobei die entsprechenden Häufigkeitstabelle für die verschiedenen Wortabstände verwendet werden (siehe 1.C.).
Bei neuen möglichen Kandidaten, werden entsprechend neue Zeilen angelegt.

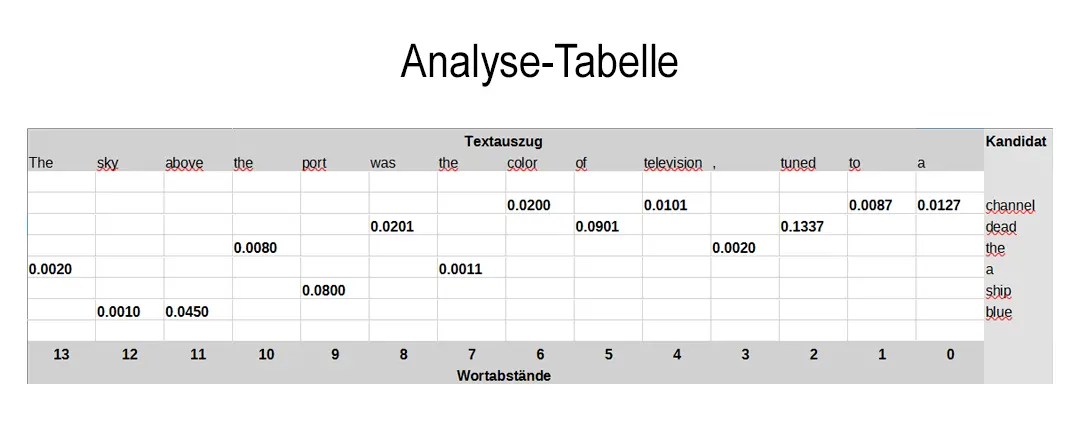
- Auffüllen der Analyse-Tabelle
Die noch leeren Felder werden mit den entsprechen Wahrscheinlichkeitswerten für die passenden Wort Kombinationen aus den passenden Wortabständstabellen aufgefüllt.
So, dass es für jede Kandidaten-/Abstands-Kombination einen Wahrscheinlichkeitswert gibt.

- Berechnung des gewichteten Durchschnitts
Für jeden der Kandidaten wird der „gewichteter“ Durchschnittswert seiner Wahrscheinlichkeitswerte berechnet. Hierfür werden bestimmte Gewichtung-Regeln benutzt.
Gewichtungsregeln
Die Regeln der Gewichtung ergibt sich aus diversen Logischen und, in dem Fall, Linguistischen Überlegungen.
Zum Beispiel:
- Nähe zum Ende des Auszugs
Worte, die näher am Ende des Auszugs stehen, beeinflussen stärker die Wahl des nächsten Wortes. Daher werden geringere Wortabstände höher gewichtet. - Satzzeichen
Auftretende Satzzeichen wie Punkt, Ausrufezeichen oder Fragezeichen deuten auf einen neuen Satz hin. Ab diesen Zeichen wird die Gewichtung der vorherigen Worte reduziert.
Bewusste Zeilenumbrüche oder Absatzwechseln, - Seltenheit von Worten
Worte die wäret der ersten Anlern-Phase (relativ) seltener gefunden wurden.
Seltener vorkommende Worte können auf spezifische Fachbegriffe oder Themen hinweisen. Diese werden stärker gewichtet, um den Kontext besser zu erfassen. - Weitere Faktoren/Regeln
Hier hat ein Linguist sicher noch weitere Ideen.
Zusätzliche Regeln können Wortarten, Stilmittel oder die Art bzw. Alter/Jahrgang der Quellen berücksichtigen. Ggf. müssen hier noch weitere Daten in der ersten Programmieren- und Anlern-Phase erfasst werden.
Jede dieser Gewichtungsregeln besteht aus zwei Faktoren.
Einen festen Faktoren, welcher dafür sorgt, dass manche Regeln immer einen stärken Einfluss auf die Durchschnittswert haben als andere. Der zweite Faktor ist ein variablem Wert, welcher die genaue Stärkte und somit Auswirkung der Gewichtung beeinflusst. Wie der genaue Wert dieser variablem Gewichtung zustande kommt wird später noch genauer betrachtet.
Die sorgfältige Planung dieser Gewichtungsregeln ist extrem entscheidend für die Qualität des A.I.-Modells. Darum wird gerade hier viel Aufwand und Qualitätsarbeit investiert werden.
- Auswahl des nächsten Wortes
Der Kandidat mit dem höchsten gewichteten Durchschnittswert wird als das Wort ausgewählt, welches möglicherweise als nächstes auf den Textauszug folgt.
- Das eigentliche Machine Learning
Alle Schritte bis hierhin waren „nur“ die Vorbereitungen für den eigentlichen Learning Prozess.
Das im vorherigen Schritt „errechnete“ nächste Wort wird mit dem tatsächlichen nächstem Wort aus dem original Text verglichen.- Wenn das berechnete Wort mit dem tatsächlichen Wort übereinstimmt:
In diesem Fall sind keine Anpassung nötig. - Wenn die Worte voneinander abweichen:
In diesem Fall wird analysiert, warum für das tatsächliche Wort nicht der höchsten Durchschnittswert berechnet wurde und wie die variablen Faktoren der einzelnen Regeln anzupassen sind, damit das richtige Wort den höchste Durchschnittswert bekommt.
Dieser Prozess, bekannt als Backpropagation, ist das Herzstück des Machine Learning.
Dabei werden Mathematisch-statistische Methoden, insbesondere Optimierungsalgorithmen wie Gradientenabstieg verwendet, um die Anpassungen optimal auf die verschiedenen anzupassenden Regeln zu verteilen.
Leider liegen diese Details wie diese Optimierungen am Besten / Sinnvollsten umsetzen werden außerhalb meines Mathematisch-statistische-logischen Verständnis.
- Wenn das berechnete Wort mit dem tatsächlichen Wort übereinstimmt:
4. Anlernen des Modells – Teil II
Dieses Programm durchläuft erneut eine umfangreiche Menge an Texten (Wieder: Je vielfältiger und umfangreicher(!) desto besser) mit jeweils sehr VIELEN Textauszügen, um so die Gewichtungsfaktoren zu verfeinern. Denn durch wiederholtes Anpassen und Überprüfen (Lernen) werden die Gewichtungsfaktor immer präziser, und das Modell verbessert seine Vorhersagefähigkeit kontinuierlich.
Damit ist die zweite Programmiere- und Anlern-Phase abgeschlossen und das A.I.-Modell ist fertig zur Nutzung.
5. Nutzung des A.I.-Modells
Um das fertige A.I. Modell zu nutzen wird zuerst der „Dialog“ also die Eingabe/Frage/Chat des Users als „Textauszug“ benutzt. Dieser wird dann mit dem Programm aus Schritt 3. und den in Schritt 4. erlernten Gewichtungsfaktoren verarbeitet, um so so das wahrscheinlichste nächste Wort zu ermitteln. Aber es erfolgt aber keine weitere Backpropagation, es werden also keine Anpassungen der Gewichtungen vorgenommen.
Dieser Schritt wird wiederholt, wobei der „Textauszug“, jeweils um das neu „errechneten“ Wort erweitertet wird. Damit wird dann auf Basis dieses erweiterten „Textauszug“ wiederum das wahrscheinlichste nächste Wort ermittelt. Und so on …
So entsteht eine (mehr oder weniger) menschenähnliche Antwort/Reaktion, der zur Eingabe des Nutzers passt. Die Qualität der generierten Antworten hängt sehr stark davon wie viel Aufwand und Qualitätsarbeit in die Entwicklung und das Anlernen des A.I.-Modells gelegt wurde. Besonders in Punkte wie:
- Qualität der Gewichtungsregeln (Abhängigkeiten)
- Effektivität der Lernalgorithmen (Backpropagation)
- Umfang und Vielfalt des Trainingsdatensatzes (Texte)
Um die Ergebnisse noch weiter zu verbessern, werden mehrere Modelle kombiniert bzw. weitere logische und/oder Linguistische Techniken zur Feinabstimmung verwendet.
Zusammenfassung
Obwohl das tatsächliche Artificial Intelligence / Machine Learning im Detail weitaus komplexer ist, sollte dieses Beispiel helfen, ein grobes Verständnis für die die grundlegende Funktionsweise zubekommen. Auch wenn die Details je nach Anwendungsfall abweichen, sind die Schritte des Grundablauf immer gleich:
- Datensammlung
Das Erfassung und Vorverarbeitung der Eingabedaten.
Egal ob das jetzt Texte; Sensoren-Daten; BWL-Daten; Bildpixel oder Steuerdaten sind. - Modellierung
Identifikation der relevanter Merkmale, Muster und Abhängigkeiten in den Daten.
Manueller Aufbau eines Modells mit Zwischenknoten (Neuronen) und Verbindungen (Gewichtungen), die ein Netzwerk bzw. eine Baumstruktur bilden und in Ergebnisknoten enden.
Hierfür müssen die A.I. Entwickler sehr eng mit den Spezialisten des entsprechenden Fachgebietes zusammenarbeiten, wie Linguisten; Meteorologen; BWLer; Steuerexperten; etc.
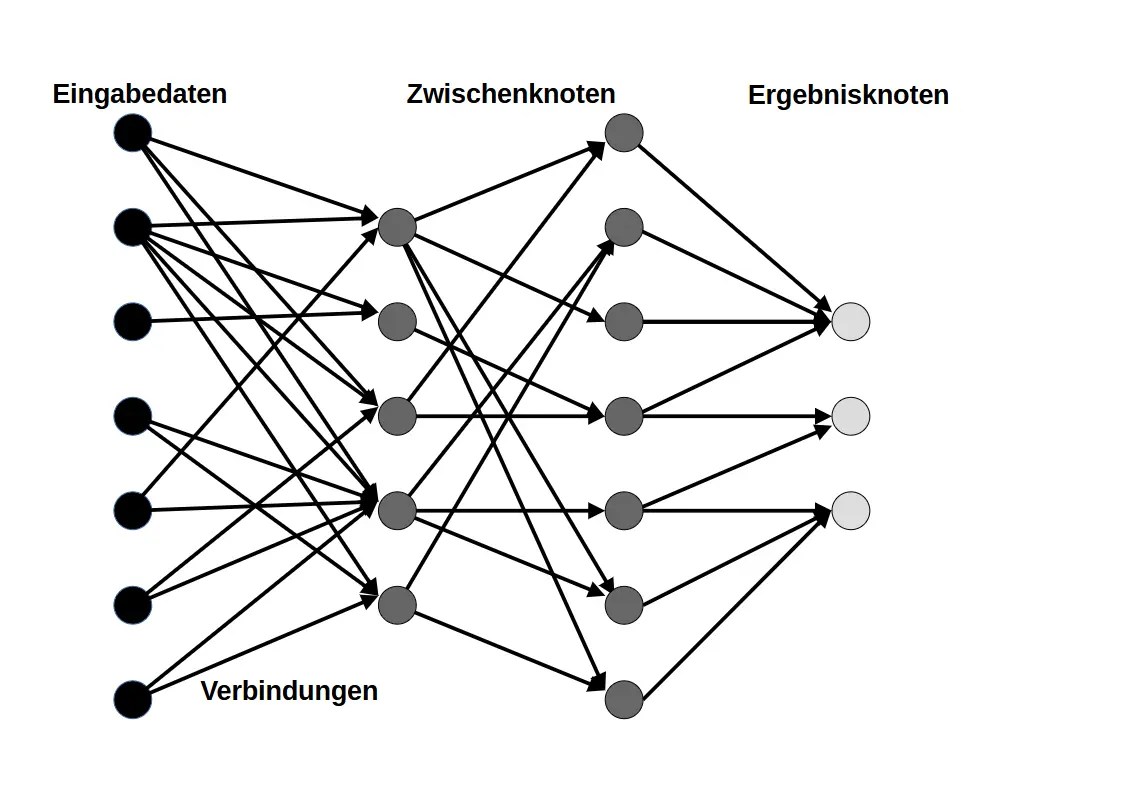

- Training
Anpassung der Gewichtungen durch Vergleich der Modellvorhersagen mit bekannten Ergebnissen und entsprechender Korrektur (Backpropagation).
Um nützliche und sinnvolle Ergebnisse zu bekommen, ist ein Training mit (extrem) große Datenmengen (Beispielen) notwendig. Neben dem Umfang der Datenmengen muss auch die Qualität der Daten stimmen und vor allem die Qualität der Vergleichsergebnisse. (Eingaben mit bekanntem Ergebnis)
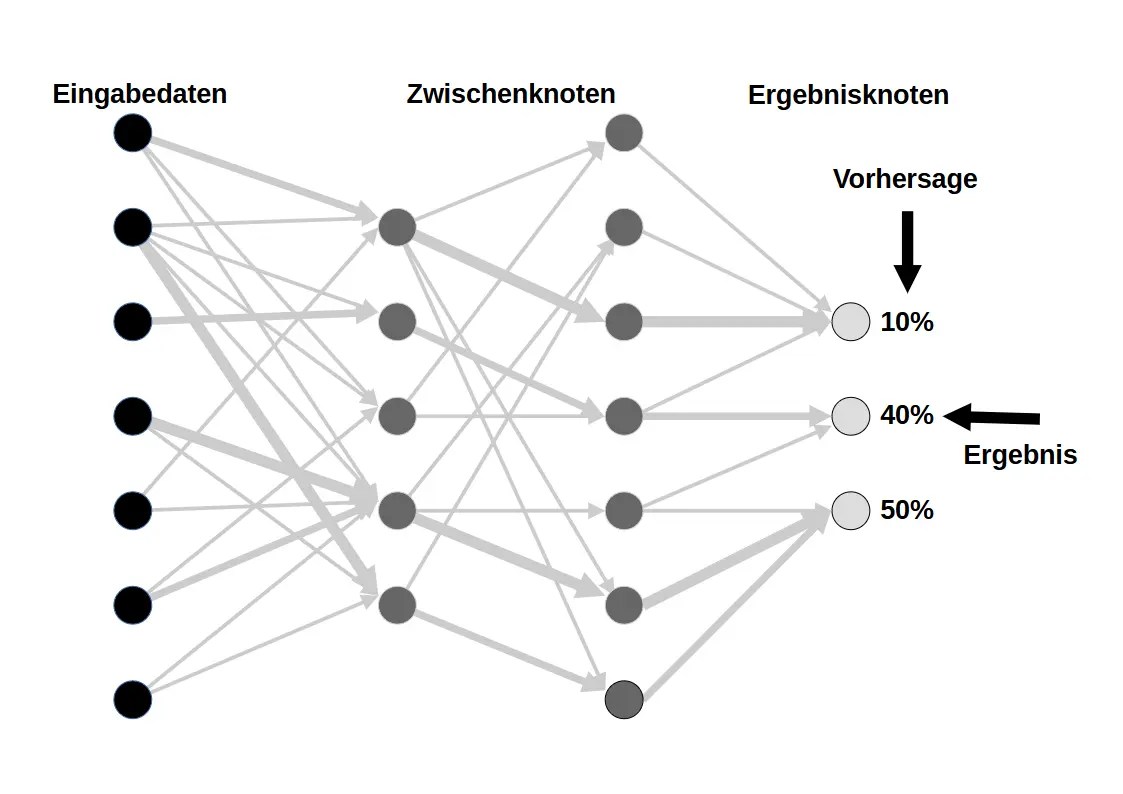

- Anwendung
Die Vorgehenden Steps sollten ein Model
Nutzung des trainierten Modells, um auf neue Eingaben sinnvolle und kohärente Ausgaben/Reaktionen zu generieren.
Durch das Verständnis dieser Grundprinzipien bekommt man auch Gefühl was A.I. kann und vor allem was nicht. A.I. ist eigendlich nur in Lage Abhängigkeiten und Muster erkennen, aber diese in einer Komplexität, Genauigkeit und Tiefe welche weit über das hinausgeht was Menschen manuell erkennen würden.
Aber die Grundabhängigkeiten müssen der A.I. zuerst manuell aufgezeigt werden. Ebenso sind zum Anlernen VIELE (Ultra viele) Beispiele/Eingaben mit bekannten Ergebnissen notwendig.
Abschluss
Ich hoffe, diese kleine Erklärung hilft dabei, die Basic-Grundlagen von Artificial Intelligence und Machine Learning besser zu verstehen. Es ist faszinierend zu sehen, wie aus „einfachen“ statistischen Prinzipien komplexe Modelle entstehen, die in der Lage sind, menschliche Sprache zu verarbeiten und darauf „natürlich“ zu reagieren.
Jetzt versuche ich auch noch die Grundlagen von text-to-image models irgendwie zu verstehen …









Kommentar verfassen :